Previous parts:
In December 2014, Der Spiegel published one of the most significant articles in the Snowden archive, exposing the scale of NSA and GCHQ efforts to break encryption and compromise encrypted communications. The article was accompanied by 44 supporting documents. One of those documents contains a previously unreported redaction failure that we believe is the most significant in any Snowden publication to date.
Almost every redaction in the document can be reversed, revealing:
- Full names of at least 14 individuals identified as NSA personnel in operational contexts.
- IP addresses of computers and networks targeted by the NSA.
- Names of companies and organizations targeted by the NSA.
A separate finding involves a screenshot of an internal NSA wiki page that, in practical terms, has never been seen. The image is embedded in the published file at full resolution but is only rendered on the page as a small thumbnail. Even at 1000% zoom in a PDF viewer, its contents cannot be read. The high-resolution version is extractable from the PDF file.
Notes on publication:
- We are not publishing any of the extracted highly sensitive content like IP addresses and people's names.
- We contacted Der Spiegel over a week ago about the issue via Signal and recommended the document be withdrawn and re-published with proper redactions. The message was successfully delivered. We have received no reply, and the document is still online in its original form. We are publishing this post to put the issue on the record.
- We are not publishing the exact steps required to reverse the redactions.
The document in question: What Your Mother Never Told You About SIGDEV Analysis.
Table of contents
- How we found it
- How we confirmed it
- How this likely happened
- An NSA wiki screenshot hidden in plain sight
- Other interesting information
How we found it
We are working through every published Snowden document with the goal of producing character-perfect plain-text transcripts (for our hopefully soon-to-be published Snowden archive project). The process often requires zooming in on the PDF to disambiguate characters, especially within embedded screenshots. This one document in the Der Spiegel set stood out immediately: its quality was exceptionally high. Text and most page elements were vector-based rather than rasterized, and even the embedded screenshots stayed sharp at extreme zoom levels, far past the point where a normal embedded image would pixelate. This was the first hint that something unusual was going on. At zoom levels around 500-1000% in Firefox, parts of the redacted content briefly became visible: the black overlay rectangles appeared to drift away from their intended positions, exposing the underlying content. The same document rendered correctly in Chromium-based browsers at every zoom level.
The cause is a precision and tiling issue in PDF.js, the JavaScript-based PDF renderer used by Firefox. At extreme zoom levels, PDF.js splits each page into multiple canvas tiles to work around browser canvas size limits. Compounded coordinate transforms across these tiles accumulate floating-point errors, and the rendering of certain elements can end up duplicated onto the wrong tile at an incorrect offset. In this document, the result is striking: the original page (with redactions intact) renders correctly, but a ghost copy of the underlying screenshot appears elsewhere in the viewport without the black overlay rectangles, because those rectangles are tied to the original tile position. Chromium-based browsers use a different rendering pipeline (PDFium) that does not exhibit this behavior, which is why the document appears fully redacted there at every zoom level.
The Firefox glitch was only the visible symptom. The underlying problem is that most of the redactions in this document were never destructive in the first place. The original, unredacted content was sitting in the PDF the entire time, just visually covered.
How we confirmed it
Once the Firefox rendering glitch hinted that the underlying content was still present in the file, the next step was to look at the PDF's internal structure directly.
A PDF is, at its core, a collection of numbered objects: text, fonts, images, drawing instructions, and the metadata that ties them together. Most of these objects are stored in compressed form to keep file sizes reasonable, which makes the raw file unreadable in a text editor. The first step was to decompress the file using qpdf, a standard open-source tool, into a form where each object's contents are human-readable.
Examining the decompressed structure of the document revealed an unusual layout. The pages themselves did not directly contain the images you see when reading the document. Instead, the page content referenced a chain of intermediate objects, form templates and tiling patterns, which in turn referenced the actual images. This nesting is one reason standard image-extraction tools didn't see anything: those tools enumerate images placed directly on pages and don't follow the indirect references this document used.
Walking through every object in the file (rather than just the page-level ones) made the actual images visible. Among them were several large objects marked as RGB images with no compression filter applied, meaning their stream contents were literally raw pixel data, three bytes per pixel, stored as-is. The black redaction rectangles were elsewhere in the file: separate, much smaller form objects whose entire content was a single instruction to fill a rectangle with black. The page content stream stacked these on top of the images at render time. Removing or ignoring them would expose the original.
Extracting the underlying images was the next step. Knowing each image's width, height, and that the data was uncompressed 8-bit RGB, the raw pixel bytes could be pulled out of the file and wrapped in a minimal image header to produce a standard, viewable image. No reconstruction or interpretation of the data was needed; the bytes were already in a usable form.
Doing this for every raw RGB image in the document produced a set of clean, fully readable screenshots, the same screenshots that appear in the published document, but without any of the black overlays.
We are not publishing the precise steps or scripts (to avoid any legal issues). The process is not difficult to reproduce for anyone with PDF format knowledge.
To our knowledge, this redaction failure is isolated to a single document. We have run the same analysis across the rest of the publicly available Snowden documents and have not found the pattern elsewhere.
How this likely happened
The evidence in the file points to a specific sequence of events.
The original presentation, produced by an NSA analyst, appears to have used cropped screenshots throughout. The author took full-resolution screenshots of analyst tools, wiki pages, and other sources, then used the presentation tool's crop function to display only the relevant portion on each slide. They sized the cropped views appropriately and added annotations like red circles to highlight specific UI elements. From the author's perspective, this is a normal and correct workflow. PowerPoint and similar tools preserve the full source image and apply a clip rectangle indicating the visible portion. This is intentional because non-destructive crops let authors adjust framing later. Tools usually provide a separate option to flatten crops destructively, sometimes labeled 'Delete cropped areas of pictures', but this is usually not the default.
Der Spiegel appears to have obtained the original source presentation file, not an NSA-generated PDF. When they exported that presentation to PDF, the export pipeline preserved the slot dimensions and the full source images but dropped the clip rectangles. The result is what we see in the published file: every screenshot is the full original image squeezed into a slot that was sized for a smaller cropped view. The proportions are visibly wrong throughout the published document. Many slides show multiple full screenshots squeezed into slots sized for cropped views, producing pages that look cluttered or layout-broken.
The red annotation circles drawn around UI elements provide additional confirmation of this mechanism. The original author drew circles to highlight specific elements on the cropped views in the source presentation. The result is circles that float in apparently empty space or sit slightly off from their intended targets. When the export pipeline dropped the clips and embedded the full source images instead, the circles stayed where they were drawn. The result is circles that float in apparently empty space or sit slightly off from their intended targets. The misalignment is itself evidence of the export failure.
The redactions were then added on top of this PDF. The structural evidence for this is clear: the redaction rectangles exist as discrete form objects layered on top of the page content, rather than being baked into the page rendering. If the redactions had been added in the presentation file before export, they would have been flattened into the rendered output. Their presence as separate overlay objects indicates they were added in a second pass after the export.
From a visual review perspective, the redactions themselves look correct: the black rectangles cover the regions of the screenshots that show sensitive content. But beyond that, the published file should have raised questions on its own. Many slides look visibly wrong: screenshots squeezed into the wrong proportions, multiple full screenshots crammed into slots clearly sized for something smaller, red annotation circles floating in empty space or pointing at nothing recognizable. None of these are subtle. They are the kind of visual artifacts that a reviewer paying attention to whether the document looks right should have noticed and asked about.
The cost of the missed review is the content the redactions were covering. When the redactions are removed from the screenshots, the extracted content includes at least 14 full names of NSA personnel in operational contexts, IP addresses and the names of companies, ISPs, and organizations the NSA was targeting, and internal NSA infrastructure references including URLs to internal tools visible in the screenshots. It also includes a high-resolution extracted screenshot of an internal NSA wiki page that has not previously appeared in any reporting.
An NSA wiki screenshot hidden in plain sight
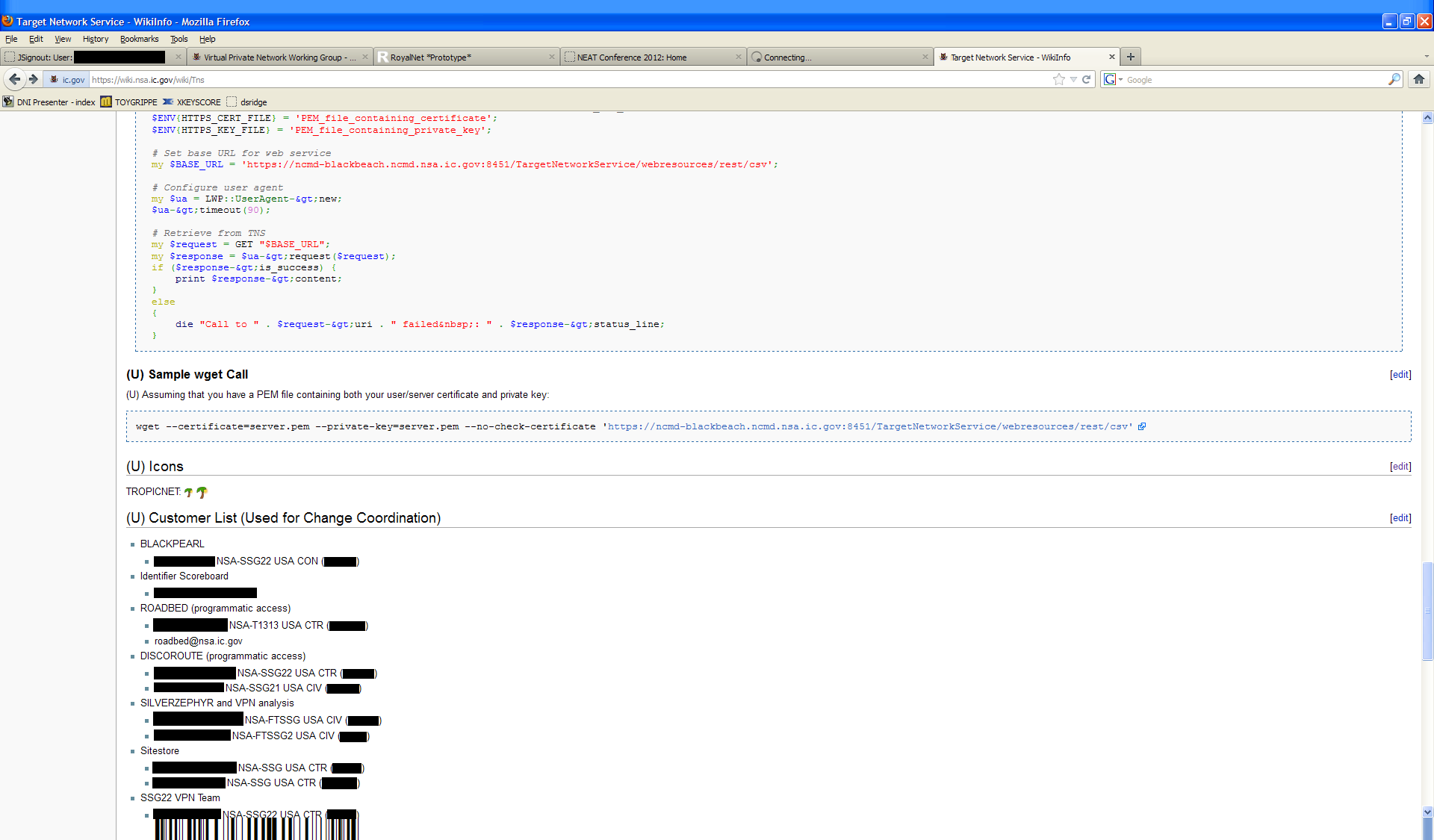
Here is the full resolution image, a previously unseen screenshot extracted from the PDF. The redactions were added by us.
A tiny thumbnail of this screenshot is visible on page 77, but even when zoomed to 1000% it remains too small for the text to be anywhere near readable. The slide it sits on explains how it likely got there.
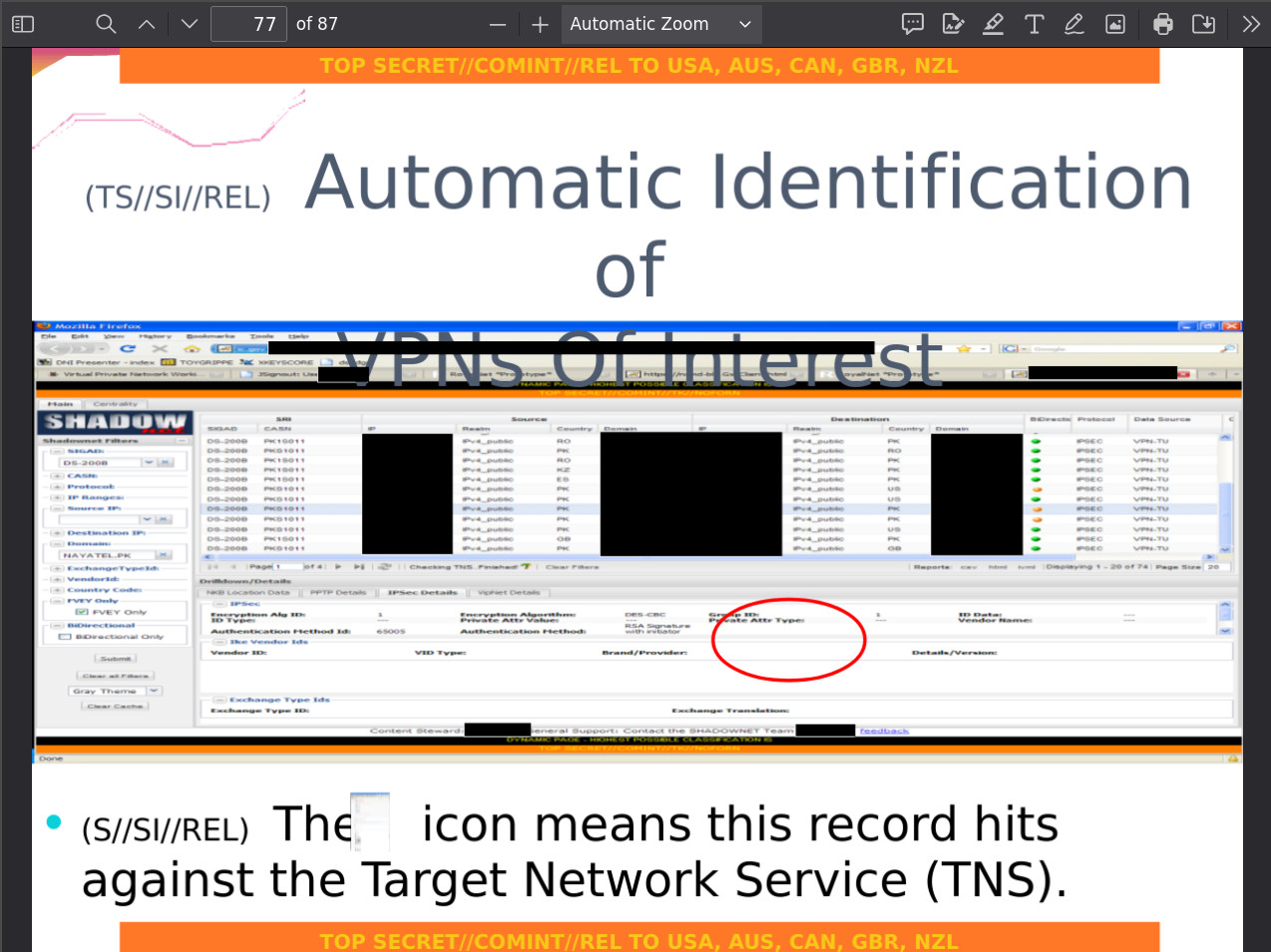
The bullet text on that slide reads: "The icon means this record hits against the Target Network Service (TNS)." The author was referring to a small palm-tree icon used in the SHADOWNET interface to flag VPN records that hit known targets. They appear to have taken a screenshot of the TNS wiki page, which includes an 'Icons' section documenting that exact palm-tree icon (labeled TROPICNET, a previously unreported codename and does not appear in any other published Snowden documents). They inserted it into the slide intending to crop down to just the icon. The crop made the icon visible on the slide at roughly icon size, but the full source image of the wiki page remained embedded behind it, just like every other cropped screenshot in the document.
A red circle was also drawn on the slide to highlight the same icon as it appears in the SHADOWNET interface above. Because of the export-strips-clips behavior described earlier, the circle ends up misaligned in the published file: it floats in apparently wrong position rather than pointing to the icon. With the redactions removed and the full source images recovered, the circle's intended target becomes clear. It points to a small palm-tree icon next to one of the IP addresses in the SHADOWNET results table. Below is the relevant section with redactions removed revealing the icon (IP addresses and domains are still redacted by us):
This is also why the wiki screenshot was embedded in the file at all. It wasn't unintentional or a leftover interactive element. It was a deliberate inclusion meant to be cropped down to a single icon for inline use in the slide text. The crop worked visually during authoring. The export step dropped the clip and preserved the full source image, exactly as it did for every other screenshot in the document.
To understand the significance of this screenshot, some context about the document itself is needed. The full presentation is 87 pages long, so there is a fair amount to unpack.
In plain terms the document is a training manual and capability demonstration for NSA analysts who track targets through encrypted VPN connections. It shows how analysts work backward from intercepted router configuration files which contain the passwords and network maps needed to understand and potentially decrypt VPN connections, and how they cross-reference multiple databases to build a complete picture of a target's encrypted network infrastructure. The DARKSUNRISE screenshots provide a direct view of how NSA operationalizes VPN intelligence at scale, showing hundreds of specific encrypted connections between Pakistan and countries across Europe, Asia and the United States being tracked in a single analyst interface.
For readers who want the full breakdown of the 87-page presentation, expand the section below.
Read the full document breakdown
The document is a presentation from NSA's Network Analysis Center, produced by SSG21 Net Pursuit and SSG22. The document covers two related topics: operational tradecraft for VPN signals development using existing tools, and the prototype DARKSUNRISE VPN analytics tool under development as a joint CES/NAC collaboration.
The first half of the document covers the analyst toolkit for VPN network knowledge building. DISCOROUTE is described as the NAC's router configuration database -- a project to acquire, parse, database and display configuration files from network devices collected through passive interception and TAO (Tailored Access Operations, NSA's elite hacking unit) active operations. The document explains DISCOROUTE's three manifest tags in detail: K for configs containing crypto keys, H for configs where TAO has a presence on the router, and M for multihop configs where an administrator telnetted through multiple devices. Separate parsers exist for Cisco, Huawei and Juniper devices to extract VPN endpoints and pre-shared keys. The document provides actual router configuration excerpts showing VPN pre-shared keys, SNMP community strings, usernames and domain names extracted from target devices -- including a Huawei and a Juniper configs with base64-encoded PSKs. A worked example traces discovery of Somalia's Hormuud network through iterative DISCOROUTE and BLACKPEARL searches, ultimately compiling approximately 400 IP addresses for over 50 devices passed to TAO. A second example shows TOYGRIPPE being used to map an Iranian corporate intranet with branches in Izmir, Istanbul, Malaysia, Armenia, Ankara and South Korea, all connected through a hub in Tehran, with two anomalous VPN connections outside the expected corporate network flagged as suspicious.
BLACKPEARL is described as a NAC tool for automated DNI link and network characterization against survey collection, supporting VPN reports, MPLS analysis, five-tuple analysis and inner tunnelled IP discovery. NKB is the corporate Network Knowledge Base delivering target communications DNI and enrichment data, with RONIN as a device characterization database providing server analytics, wiki VPN metadata and VPN analytics. GNETWORK GNOME extracts and correlates information from NAC, SSG, SSO, NTOC and other metadata databases. ROYALNET and TREASUREMAP are mentioned as additional tools in the analyst workflow.
The second half introduces DARKSUNRISE, a prototype VPN analytics tool developed as a joint CES/NAC collaboration storing data in MDR-2, the corporate metadata repository holding the DNI metadata. The SHADOWNET interface screenshots, the most operationally revealing content in the document, show live VPN data from MUSCULAR (DS-200B) filtered to Pakistan-related connections, displaying 236 IPSec VPN connections between Pakistan and counterparts in Romania, Turkey, UAE, Czech Republic, Singapore, Kazakhstan, Spain, the UK and the US. The drilldown views show NKB geolocation data resolving specific IP addresses to Bucharest/Romtelecom, Karachi/Micronet Broadband and Islamabad/Nayatel. The IPSec details drilldown shows encryption parameters including AES-CBC and DES-CBC, authentication methods and Microsoft Vista/Longhorn vendor IDs. The centrality tab identifies VPN hub nodes by counting how many other VPNs connect to a base IP. The metrics tab shows VPN type counts broken down by SIGAD, with a total of 307,181 VPN records across different sites. The Target Network Service integration flags VPN connections hitting against known targets
This previously unseen extracted screenshot shows a part of the TNS (Target Network Service) NSA WikiInfo page, the internal documentation for the web service that powers the target-flagging icons visible in the DARKSUNRISE SHADOWNET interface. TNS is a REST web service running on ncmd-blackbeach.ncmd.nsa.ic.gov:8451/TargetNetworkService/webresources/rest/csv that provides a machine-readable list of IP addresses associated with known targets, delivered as a CSV file. The screenshot shows a part of the API access code (a Perl LWP::UserAgent call and a wget equivalent) that other NSA tools use to query TNS programmatically and check whether a given VPN endpoint belongs to a known target. This is what powers the filled circle icons in DARKSUNRISE indicating a VPN connection hits against the Target Network Service.
The customer list shows which tools consume TNS data, confirming the integration between the VPN analytics ecosystem. BLACKPEARL, DISCOROUTE and ROADBED all access TNS programmatically, as does SILVERZEPHYR's VPN analysis function and the SSG22 VPN Team. The Identifier Scoreboard also appears as a TNS customer. The customer list effectively maps the NSA VPN targeting infrastructure showing that target IP flagging from TNS flows into router configuration analysis, link characterization, VPN analytics and the SILVERZEPHYR upstream collection program simultaneously, meaning a single target designation propagates across the entire VPN intelligence pipeline automatically.
One last thing worth noting. In 2014, the New York Times suffered a much smaller redaction failure in a Snowden document. One analyst's name and one targeted network, in a file where the redactions could be defeated by highlighting and copying the text. That failure was caught quickly and prompted significant press coverage about the dangers of careless redaction in sensitive document publishing. The failure described in this post is more than an order of magnitude larger by every measurement: names of personnel, organizational targets, network identifiers, and a previously unseen embedded screenshot. It has been online, undetected, for over eleven years.
Other interesting information
- The extracted screenshot shows the TNS API running on the "ncmd-blackbeach" subdomain, while the main document shows the DARKSUNRISE tool running on "ncmd-blacksand". Both subdomains share the "ncmd-" prefix (which likely stands for NSA/CSS Maryland) and the "BLACK" element. Neither BLACKBEACH nor BLACKSAND appears anywhere else in the published Snowden documents. BLACKPEARL, mentioned several times in the same document, also begins with "BLACK", suggesting a shared codename family for related tools and projects. This kind of prefix grouping is a common naming pattern at the NSA, as seen for example in the QUANTUM family (QUANTUMINSERT, QUANTUMNATION, QUANTUMTHEORY etc.) and others.
- Several screenshots in the document show "Potluck" appearing in the browser's search engine field, suggesting it is an internal NSA or IC search engine. This codename does not appear in any other published Snowden documents and we found no public references to it elsewhere.